vol.4
「計算科学×データサイエンス×HPC」で
材料開発を革新する

材料開発にデータサイエンスの手法を取り入れ、材料開発を効率化・高度化しようという「マテリアルズ・インフォマティクス(MI)」。機械学習の進展によって材料開発でのMIの利用が進む中、大きな壁となっているのが「材料データの不足」です。この課題を解決する方法として、大規模シミュレーションによって機械学習に適した材料データベースを生成しよう、という取り組みを行っているのが、住友化学の西野さんのチームです。「計算科学×データサイエンス×HPC」というアプローチによる、新しい材料開発を紹介します。

材料開発の革新
「マテリアルズ・インフォマティクス(MI)」
材料開発は、これまで多くの部分が研究者・技術者の勘と経験に頼って行われてきました。しかし、近年、顧客のニーズが多様化し、研究開発期間の短縮が求められる中で、従来の「職人技」に頼った材料開発のやり方では対応が難しくなってきているといいます。
このような状況の下、AIやデータサイエンスを材料開発に利用することで、材料開発期間を大幅に短縮し、これまでにない画期的な材料を見つけようという取り組み、MIが注目を集めています。住友化学の西野さんは、材料メーカーの中で、MIを実際の材料開発に活用する取り組みを精力的に行ってきました。
「たとえばスマートフォンの新機種が出るたびに、材料メーカーは、より美しく見えるディスプレイや長時間使用できる電池を実現するために、新しい材料を開発することが求められます。この要請に従来の材料開発のやり方で対応していては時間もかかるし、新しい材料を見つけるのも難しくなってきています。これまでとは異なる材料開発の方法が必要だという意識は材料メーカーでも強まっていて、その答えの一つとしてMIがあります。」
解説1
材料開発におけるMIの応用先
MIは、次に示すような材料開発のタスクを改善すると期待されている。
ある候補材料のグループの中からもっとも適した材料を短時間で見つけ出す
事例1:機械学習を用いた16億分子のスクリーニングを実施し、外部量子効率22%のOLED(有機発光ダイオード)材料を発見 (R Gómez-Bombarelli, et al., Nature Materials 15, 1120–1127 (2016))
要求される材料特性(所望特性)を満たす材料を見つける
事例2:ベイズ推定を利用した逆問題を解く事により所望特性を満たす分子構造を提案するシステムの構築に成功 (H. Ikebata, et al., J. Comput Aided Mol Des (2017) 31: 379-391)
目標分子を効率的に合成するプロセス(経路)の探索
事例3:文献データから合成経路を学習し、合成経路を提案。正解率50%以上を達成 (M. H.S. Segler, M. P. Waller, “Modelling Chemical Reasoning to Predict and Invent Reactions”, Chem. Eur. J. 2017, 23, 6118, Copyright Wiley-VCH GmbH)
ある材料特性を調べるためのもっとも効率的な材料実験の計画立案
事例4:既に保有しているデータをもとに次の実験ポイントを決定するベイズ最適化を使い、少ない試行回数で熱電変換材料の最適構造を発見 (S. Ju, et al., Phys. Rev. X 7, 021024 (2017))
課題は材料データの不足
MIでは、機械学習によって予測モデルを作り、そのモデルを使って候補となる材料の特性や合成経路などを予測します。ここで重要になるのが、研究者や技術者の勘と経験の代わりとなる予測モデルと、それを作り出すための「材料特性のデータ」です。しかし、創薬などの他の分野と比べると、材料データベースの整備はとても遅れている、と西野さんはいいます。
「現状、世の中でビッグデータの活用が進んでいるのはデータが集まりやすい分野だけで、残念ながら、材料分野のデータはとても少ないのが実情です。特定の開発ターゲットに絞って、欲しい特性やプロセス条件が揃った材料データを探そうとすると、多くても100件しかない、ということもあります。このような材料データの不足が、MIの導入にとって、もっとも大きな課題です」
この問題を解決するために西野さんが着目したのが、大規模シミュレーションによって材料データを生成する、というアイデア。まず、数値シミュレーションによって、対象となる材料特性のメカニズムを解明し、材料特性をより低い計算コストで推定できる「記述子(材料特性を表す物理量)」を見つけます。そして、その記述子をもとに生成した材料データベースを使って機械学習を行うのです。
「HPCを使った大規模シミュレーションによって、まだ得られていない材料データを得ることができれば、材料開発の競争力を強化できますし、そのデータとMIを組み合わせれば、MIの生み出す価値が大きく広がります。『計算科学×データサイエンス×HPC』という組み合わせで材料開発を革新できないだろうか、と考えました」
大規模シミュレーションと機械学習の融合
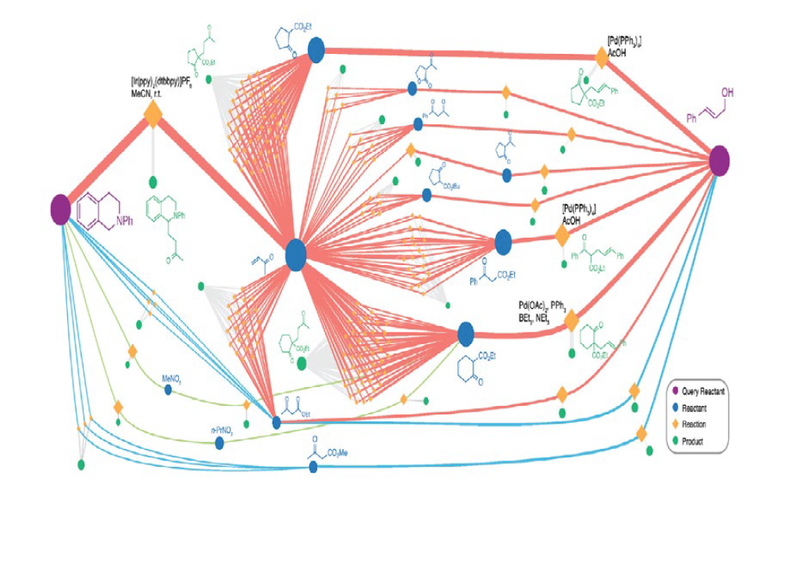
このアプローチを使って西野さんが行った取り組みのひとつが、最近スマートフォンやテレビに使われるようになった有機EL材料の開発です。有機EL材料の発光特性を決める重要な物理現象に、材料中の電荷の移動(ホッピング)があります。西野さんは、この電荷移動のメカニズムを解明するため、鳥取大学大学院工学研究科の星健夫准教授の協力を得て、大規模量子シミュレーション(波束ダイナミクスシミュレーション)を行ないました。この計算は高度なアルゴリズムと強力な計算資源を必要とするため、2019年当時、最速の計算機だった最先端共同HPC基盤施設(JCAHPC)のOakforest-PACSシステムを利用しました。
西野さんは、数値シミュレーションの結果をもとに有機EL材料中の電荷移動のメカニズムを分析し、電荷の移動がIPR(Inverse Participation Ratio)と呼ばれる物理量を記述子として評価できることを見出しました。そして、このIPRによって材料特性を整理することで、機械学習に適した材料データベースを生成することに成功しました。
「機械学習を行う際には、材料の分子構造そのままではなく、ある特徴を抽出してそれをインプットとして使う方が、より良いモデルになることが多いのです。一般に、何らかの基礎理論に基づいているモデルの方が、汎用性が高いためです。この時、どういう記述子に落とし込むかというところが重要で、これは純粋なデータサイエンスだけでは気づくことは難しく、物理や化学の知識、あるいは実際にその材料を扱った経験が必要です。そのような知識や経験があれば、この部分を特徴量(機械学習に適した物理量)に落とし込めるだろう、数値化できるだろう、と気づきやすいのです」
解説2
有機EL材料内の電荷移動の
大規模量子シミュレーション
有機EL材料の発光特性を決める重要な物理現象が、分子内の電荷の移動(ホッピング)だ。今回の研究では、ホスト分子とゲスト分子(錯体)の組み合わせが異なる十数種類の有機EL材料について、量子波束ダイナミクスシミュレーションを行い、材料分子中の電荷移動を調べた。この数値シミュレーションは、HPCを使った大規模シミュレーションの専門家、鳥取大学大学院工学研究科の星健夫准教授が担当した。
下の図は、このシミュレーションで得られた有機EL分子中の電荷の移動を可視化したもの。ある錯体から別の錯体に電荷が移動する際、両者の波動関数が重なる、というメカニズムが解明され、電荷移動の特性はIPRという物理量で記述できることが見いだされた。IPRの算出は量子シミュレーションに比べてはるかに計算量が少ないため、材料特性の推定の計算負荷を大幅に削減することができる。この記述子の「発見」では物性理論の知識と経験が大いに役立ったという。

波束ダイナミクスシミュレーションによる、波束伝播の様子。青色部分はホール波束、すなわち、電荷の位置を示す。電荷の不連続な移動(ホッピング)が生じている。
今回、西野さんが見つけたIPRという記述子は、物性の基礎理論で扱われる物理量で、材料分野でこれまでほとんど使われていなかった、といいます。
「私はかつて物性理論の研究をやっていたので、IPRという記述子に気づくことができました。また、プロジェクトメンバーには、材料開発の現場にいる方、計算科学の専門家、データサイエンスの専門家もいます。HPCI運営の代表機関であるRISTからもサポートが得られています。そういうダイバーシティ(多様性)を持ったチーム構成が、今回の成果につながったのだと思います」
解説3
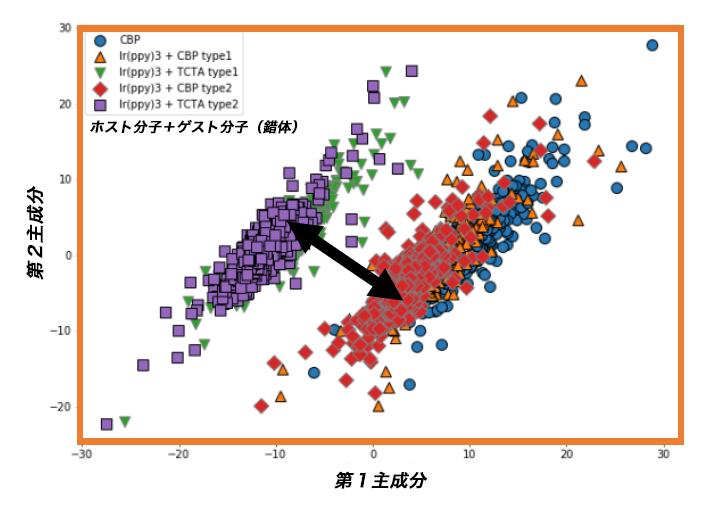
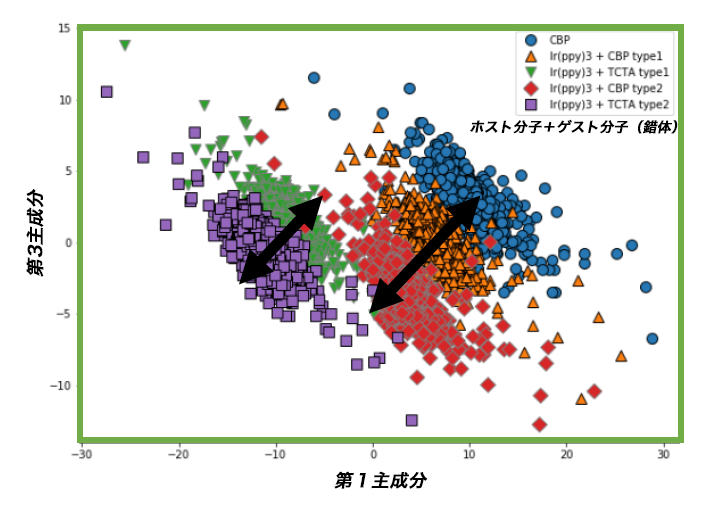
記述子による材料分類の検証
記述子IPRによって、有機EL材料を正しく分類できるかどうかを検証した結果を示す。IPRは多次元パラメータであるため、主成分分析によって次元数を減らして検証を行った。上の図はホスト分子とゲスト分子(錯体)の組み合わせを変えた場合、下の図は錯体の濃度を変えた場合を示す。どちらの場合もIPRを記述子として、ホスト分子・ゲスト分子の組成が異なる材料を明瞭に分類できた。この結果はIPRを記述子として整理した材料データが、有機EL材料の発光特性の機械学習による推定に有効であることを示唆している。
MIから「サイバーフィジカルループ」へ
「富岳」をはじめとするHPCI資源を活用しながら、「計算科学×データサイエンス×HPC」という新しい材料開発のアプローチをさらに先に進めていきたい、と西野さんはいいます。
「これからは、他の人が取れないデータを作ることや、まだわかっていないメカニズムを明らかにすることがより重要になるでしょう。このため、HPCを使った先端的なシミュレーションや、それによるデータ生成はさらに重要になってくると思います。今後取り組みたいのは、比較的シミュレーションを行いやすい材料系で機械学習のモデルを作って、そのモデルをデータの作りにくい領域でも使うという方法です。これは『転移学習』と呼ばれ、画像解析でよく使われてきた方法なのですが、材料開発でも活用できると考えています」
さらに先には、「理論・実験・シミュレーション・データサイエンス」の4つをつなげた、より高度な「データ駆動型材料開発」を実用化したい、と西野さんは考えます。
「現在は、理論と計算科学とデータサイエンスの組み合わせですが、これに実験を加えて、実験で得られた知見から新たな理論やモデルを作り、そのモデルによるシミュレーションによって新しいデータを作る、『サイバーフィジカルループ』と呼ばれる材料開発サイクルの実現が、『MIの次』の目標です。そして、MIやサイバーフィジカルループを使いこなす人材を育成することで、持続的に価値を創出できる体制を作ることが、私の役目だと思っています」
研究者紹介

大学では物性の基礎理論を研究し、大学院とポスドクで基礎理論とシミュレーションを組み合わせた材料研究に取り組んだ西野さん。その時に、現鳥取大学の星さんと共同で開発したソフトウェアが今回の数値シミュレーションでも使われているそうです。西野さんがMIに興味をもったのはポスドク時代。国内のある自動車メーカーの依頼を受けてリチウムイオン電池用材料の数値シミュレーションを行った時、海外の競合会社が、候補材料の検討にMIを使う様子を目の当たりにして、この分野の大きな可能性を感じたといいます。物性理論と大規模シミュレーション、実際の材料開発、それぞれに深く携わってきた西野さんの経験がMIのフロントランナーとして活躍するための大きな力になっているのでしょう。
研究課題名:
大規模量子シミュレーションと機械学習を用いた有機半導体材料設計(hp190066)
大規模量子化学計算によるデータ生成と機械学習を統合した有機半導体材料設計(hp200049)
課題代表者:住友化学株式会社 西野 信也
データ同化研究20年

データ同化の研究を生業としています。データ同化は、シミュレーションと実測データを結ぶ方法で、数値天気予報の根幹です。私がデータ同化と出会ったのは、ちょうど20年前の2001年でした。当時気象庁総務部企画課で仕事をしていた時、佐藤 信夫数値予報課長(当時)が突然私の席まで来られて、数値予報課報告・別冊第43号「データ同化の現状と展望」を置いて行かれました。
2002年4月に予報部数値予報課に異動となり、当時まだ開発中だった気象庁非静力学モデルのための新しいデータ同化システムの開発を仰せつかり、2003年6月に米国メリーランド大学に留学するまでの1年ほどの間、必死になってプロトタイプシステムJNoVA0(ジェノバ・ゼロ)を開発しました。JNoVAはJMA Nonhydrostatic-model-based Variational data Assimilation(気象庁非静力学モデル変分法データ同化)の略で、後に実際の天気予報システムとして実用化されましたが、その命名に私が一役買ったことや、バージョン0の存在は余り知られていません。わずか1年ほどでJNoVA0を開発したことが基礎となり自信となって、メリーランド大学最短記録とも言われる2年間で博士課程を修了し、その後の研究を進めてこられたと思います。
2012年にメリーランド大学で教鞭を執っていた頃、当時の計算科学研究機構でデータ同化の研究者を探しているという話を聞き、世界一のスーパーコンピュータ「京」に惹かれて日本へ帰ることにしました。パーマネント職を2回も蹴るなんて、と言われもしましたが、飛躍にリスクはつきものです。「京」のパワーをどう使って世界一の研究をするか、そればかりを考える日々が続き、新型センサによる桁違いのビッグデータを使った「ビッグデータ同化」の研究に着想しました。「京」を生かして30秒毎に更新するゲリラ豪雨予測システムを開発し、2020年の夏、いよいよ筑波大・東大のスーパーコンピュータOakforest-PACSを使ったリアルタイムのゲリラ豪雨予報実験に成功、今年は「富岳」を使って東京オリンピック・パラリンピック期間に合わせた予報実験を実施しています。
データ同化はシミュレーションと現実世界を結びます。天気予報だけでなく、様々なシミュレーション分野にも応用が広がってきており、今後の発展に尽くしたいと思っています。
次回は、上記ゲリラ豪雨予測システムに取り組み始めた2013年当初から苦楽をともに研究してきた富田浩文チームリーダーにつなぎます。
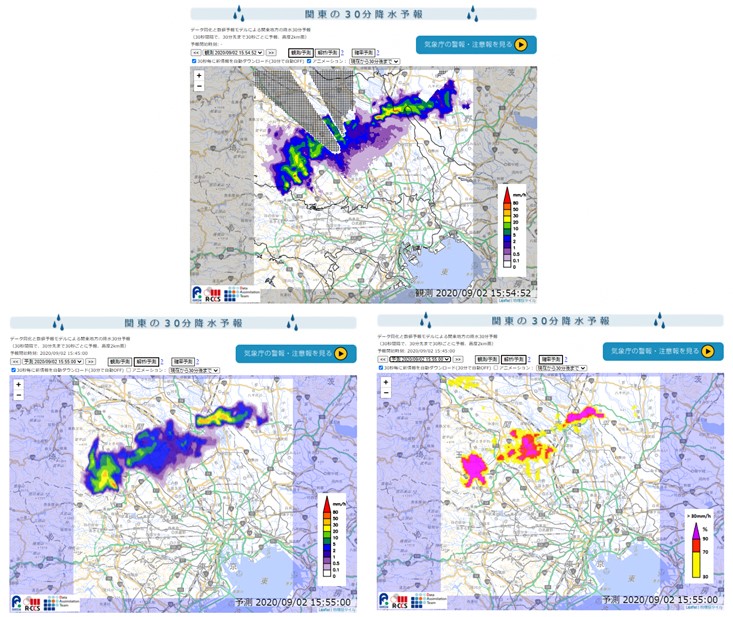
ゲリラ豪雨予報実験のWeb画面イメージ(上:観測データ、左下:10分予報、右下:強い雨の確率)